
Editor's Note: This text is an edited transcript of the course Dysarthria: Best Practices for Assessing Intelligibility, presented by Kimberly Dahl, MS, CCC-SLP.
(*See handout for a larger version of all images included in the article.)
Learning Outcomes
After this course, participants will be able to:
- List two valid methods of assessing intelligibility.
- Describe common methods of assessing intelligibility.
- Identify three factors that may bias intelligibility estimates.
Introduction
Before I begin, I'd like to start with a few acknowledgments. Much of what I'll be presenting draws on the work of various researchers and clinicians, though I will also share some of my own research. I want to acknowledge the contributions of my colleagues in the STEP Lab at Boston University for their support in carrying out this work, as well as the funders who made it possible, specifically the NIDCD and CAPCSD.
What is Dysarthria?
I understand that many of you have varying levels of experience in assessing intelligibility and working with individuals who have dysarthria. Some of you may have been doing this for many years, some may be early in your careers, and others may be transitioning into new populations or areas of practice. So, we'll begin by covering some foundational topics to ensure we're all on the same page, starting with the question: What is dysarthria?
Dysarthria is not a single speech disorder but rather a group of motor speech disorders characterized by abnormalities in the movements required for speech production. These abnormalities can affect the strength or speed of the movements, the range of motion, or the tone and accuracy of those movements. Any of these aspects can be impacted in individuals with dysarthria.
Sometimes we refer to "the dysarthrias" in the plural, as the term encompasses various subtypes of dysarthria, each defined by distinct perceptual characteristics and the underlying etiology of the disorder. Some of those different types are listed here:
- Flaccid
- Spastic
- Ataxic
- Unilateral upper motor neuron
- Hypokinetic
- Hyperkinetic
- Mixed
- Undetermined
What is Intelligibility?
Today, we're going to take a broad, big-picture approach. When we talk about intelligibility, we're referring to the degree to which a listener understands the speaker's message. I don’t mean understanding in an empathetic or emotional sense, but rather the literal decoding of the words that the speaker is producing. Intelligibility is inherently a perceptual outcome, meaning we're capturing the listener’s perception of what the speaker says.
The outcome of intelligibility can be influenced by factors like acoustics, muscle activity, and other physical aspects, but ultimately, intelligibility is a perceptual outcome. It’s reduced when the listener cannot effectively decode the speech. Intelligibility is a core functional deficit in dysarthria, making it a crucial measure that is frequently tracked in both clinical practice and research. However, as I mentioned earlier, changes in intelligibility occur across all dysarthria subtypes. Therefore, it does not specifically predict the subtype, etiology, or which speech subsystems might be impaired. In fact, reductions in intelligibility can result from a combination of symptoms or impairments across different speech subsystems.
Assessing Intelligibility
When we assess the critical outcome of intelligibility, we are aiming to capture naturalistic interactions where a speaker produces speech, and the listener receives and perceives that speech. Ideally, the speaker’s message and the listener’s perception are identical. However, when we measure this interaction and perception of intelligibility, it is often done in an asynchronous setup. We might record our patients, clients, or research participants as they speak, and then later present that recording to a listener who will document what they perceive the speaker to have said. We then quantify the degree to which the intended speech and the perceived speech match. The goal of this process is to develop a process that provides the most accurate estimate of the speaker's intelligibility.
In order to achieve this, we face several key decisions in designing our process. These decisions fall into at least three major areas: First, what method will we use to quantify intelligibility? Second, what speech sample will we present to listeners as the basis for their perception? And third, who will our listeners be?
This will be the structure of this course. We’ll address each of these areas separately, and at the end, we’ll bring them all together. We’ll approach this by asking what key questions we need to consider in each domain, what evidence is available to help us answer those questions, and what our takeaways are based on that evidence.
Method
Let’s start with the method. What approaches can we use to assess intelligibility? In a survey of practicing SLPs who assess intelligibility as part of their clinical work, Gurevich and Scamihorn found that SLPs report using both formal and informal assessments (2017). Formal assessments refer to standardized, published instruments, while informal assessments are non-standardized, though they may still follow structured approaches. We’ll define these informal methods in more detail shortly. Additionally, the respondents noted that they use oral mechanism exams, evaluate diadochokinesis rates, and conduct cranial nerve exams as part of their assessment of intelligibility.
Now, some of you may be feeling uneasy as you hear these approaches mentioned in the context of assessing intelligibility—and you’re right to feel that way. The key question is: If intelligibility is meant to quantify the listener's perception of speech in a natural interaction, how do these methods capture that? The answer is—they don’t. While oral mechanism exams, diadochokinesis, and cranial nerve exams are essential components of a comprehensive motor speech evaluation, they do not measure intelligibility, which is a perceptual outcome based on the listener’s ability to understand the speaker.
So, moving forward, we’ll set aside these approaches and focus on methods that are valid for assessing intelligibility specifically.
Formal Assessments. Let’s begin by discussing formal assessments. This is not an exhaustive list, but these are some of the more commonly used tools or those that appear frequently in research. They include the Assessment of Intelligibility of Dysarthric Speech (AIDS) and its software-based counterpart, the Speech Intelligibility Test (SIT), which are closely related. Then, we have the Frenchay Dysarthria Assessment (FDA), the Dysarthria Examination Battery (DEB), and the Dysarthria Profile. These last three are more comprehensive motor speech assessment tools, not exclusively designed for assessing intelligibility, but each includes a component that quantifies intelligibility.
When considering which formal assessment to use—or if you're thinking of incorporating one of these tools into your practice—you'll want to ask yourself a few key questions. First, is there evidence that the tool is reliable for assessing intelligibility? Is it valid for measuring this outcome? And is it applicable to the person you’re assessing? For example, you wouldn’t want to use a tool normed on adult speakers to assess children. These are essential questions to ensure the tool fits your needs.
Additionally, cost is an important consideration. The expense of formal assessments can sometimes be a barrier to their use in clinical practice, so this is another factor to weigh when deciding which tools to incorporate.
Formal Assessment Evidence. Now, let’s turn our attention from the question of how to assess intelligibility to the evidence supporting these tools. Specifically, we want to examine the psychometric properties of these assessments to determine whether they should be incorporated into practice. When evaluating these tools, we look at their reliability and validity—essential qualities to ensure that an assessment is both consistent and accurately measures what it claims to measure.
In a very broad sense, we can represent the evaluation of these tools with check marks for each type of reliability and validity that has been demonstrated (see figure below).
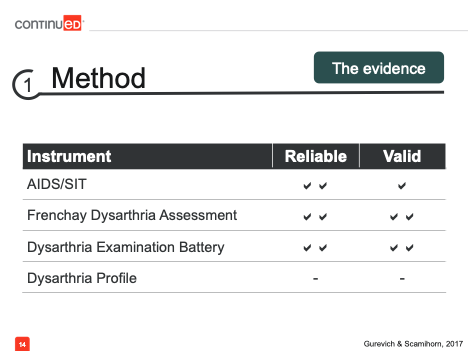
One thing we see immediately is that, for the Dysarthria Profile, there is no current evidence supporting its reliability or validity. This is an important consideration when deciding which formal assessments to incorporate into your practice. In contrast, the other tools on this list do have some form of evidence for their reliability and validity.
Informal Assessments. Formal assessments are just one option, but SLPs often rely more heavily on informal assessments, so let's take some time to discuss those in more detail. Here are a few of the options for informal assessments.
- Orthographic transcription
- Visual analog scale
- Percent estimation
- Interval scale
These methods of informal assessment might resemble those used in published, standardized instruments, but they are applied in a non-standardized way. Some common informal methods include orthographic transcription, where the listener writes or types what they hear the speaker say. We then compare this to what the speaker intended to say and calculate the number of correct words, typically resulting in a percent words correct score.
A visual analog scale (VAS) involves a line, usually 100 mm long (or 100 units if digital), where the listener marks how intelligible they thought the speaker was. This is often anchored from 0% to 100% intelligibility.
Percent estimation is when the listener simply reports what percentage of the speech they believe they understood.
An interval scale, though less commonly used, is a categorical or ordinal scale that ranges from mildly, moderately, to severely impaired intelligibility.
We can divide these approaches into two groups: orthographic transcription and the others. Orthographic transcription differs from the visual analog scale, percent estimation, and interval scale in a couple of key ways. First, it is more objective than the others, which incorporate more subjectivity, leading to greater variability in results. However, orthographic transcription is not entirely objective; anyone who has scored transcriptions knows there is some decision-making involved, which might differ between clinicians. Additionally, the time required to complete these methods varies.
Orthographic transcription demands time both for transcribing and scoring, which can be time-consuming, especially when working with multiple patients or participants. On the other hand, the visual analog scale, percent estimation, and interval scale are much more efficient.
I want to explore each of these methods in more detail because if we’re deciding between prioritizing objectivity or efficiency, we need to understand what trade-offs we may be making by choosing one over the other. So, let’s dive into that.
Informal Assessment Evidence. As we look for evidence on how these different methods compare, we can first turn to the work of my colleague Defna Abur. She evaluated the relationship between orthographic transcription ratings and VAS ratings of intelligibility by inexperienced listeners (2019). Her findings showed a strong relationship between the two ratings, with no substantial differences regardless of the method used.
In another study by Kaila Stipancic, a researcher I’ll mention frequently for her extensive work on intelligibility, inexperienced listeners were tasked with evaluating intelligibility in various speaking conditions—habitual speech, clear speech, loud speech, and slow speech (2016). This study also found a moderate relationship between the ratings, regardless of the speaking style. So, there is evidence that using a more efficient method like VAS instead of transcription is an appropriate way to assess intelligibility, though it’s important to note this was based on inexperienced listeners.
Now, let’s consider the evidence for experienced listeners, such as SLPs. How do these relationships hold up with professional ratings? Fortunately, there is research here as well. Micah Hirsch conducted work comparing percent estimation and VAS ratings by speech-language pathologists and again found a moderate relationship between the two methods (2022).
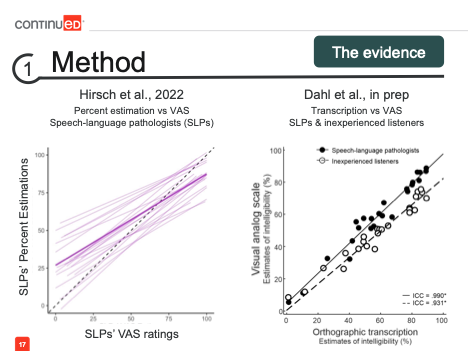
In the graph on the left, we can see the purple line indicating the relationship between the two methods. In my own work comparing transcription and visual analog scale for both SLPs and inexperienced listeners, we found near-perfect agreement between the two approaches among SLPs, represented here by the closed markers, and still very strong agreement between the methods for inexperienced listeners.
Takeaways. So, taking all this evidence together, we can conclude that when it comes to methods, our key takeaways are: formal assessments are valuable if they’re available, and if there is evidence showing they are reliable, valid, and appropriate for the client or participant. However, informal assessments are also effective for assessing intelligibility. We can choose to prioritize objectivity with orthographic transcription or efficiency with a visual analog scale.
Many of you may be using percent estimation, and while there is a smaller body of evidence suggesting a good relationship between percent estimation and VAS, we can indirectly link that to more objective methods like transcription. However, the evidence base for this relationship is still not as strong.
Speech Sample
What kind of speech sample should you collect? What should you use as the basis for your intelligibility estimates? You have options ranging from single words to longer segments of speech, like sentences and passages, and even up to conversation or monologue.
These types of speech stimuli differ in several ways. First, as we move from words to conversation, we are moving from the least to the most ecologically valid types of speech. Ecological validity refers to how well the speech captures the way people are speaking in their daily lives. Isolated words have less ecological validity, while conversation or spontaneous speech better reflects how people naturally speak. However, as we move up to conversation, the task also becomes more challenging, which is important to consider.
This additional challenge can be useful if we are targeting complex tasks with our patients, but depending on their symptoms and level of speech impairment, it may also be too difficult for some individuals. So, it's something to weigh carefully.
Another benefit of using structured stimuli like words, phrases, sentences, or passages—particularly reading-based tasks—is that the target is known. We know exactly what the speaker intends to say, which allows us to get the most accurate measure of intelligibility. In conversation, we can make educated guesses or assumptions, especially if we are familiar with the speaker, but we can never be completely certain of their target. Additionally, keep in mind that reading-based stimuli require literacy skills, which might not be appropriate for every individual, and is another factor to consider when balancing these characteristics.
Sentences. It is common for most people to choose sentences because they strike a balance between being challenging, ecologically valid, and accessible to most individuals. If you decide to use sentence-level speech samples, you may take those sentences from formal assessments, many of which provide specific sentences for you.
If formal assessments are not available, there are other sources you can use. One option is the TIMIT sentences, managed by the Linguistic Data Consortium. Like formal assessments, TIMIT sentences are not free—you need to be a member of the consortium or pay for access. Though primarily designed as a speech corpus, the transcription of these sentences can be quite useful.
The Harvard sentences are another option and are freely available as long as you have access to the publication where they are presented. These include 72 sets of ten sentences. Additionally, you can create personalized sets of sentences for your clients, tailoring them to the specific types of sentences that are most important for their intelligibility in real-life situations.
Key Considerations. When choosing the speech sample, there are some key considerations to keep in mind. The repeatability of the stimuli is important because we’ll likely be assessing intelligibility before, during, and after treatment, or while monitoring disease progression. We need something that can be repeated to get a valid measure of intelligibility each time the assessment is conducted. Another important factor is reading ability—we must consider whether reading-based stimuli are appropriate for our patient or client.
Phonetic characteristics of the speech sample are also crucial. One consideration is phonetic coverage, which means including every speech sound of a language in the sample. Phonetic balance refers to including speech sounds in proportion to how common they are in the language. Achieving this balance allows us to account for the fact that certain speech sounds may be more difficult for some speakers than others, and which sounds are challenging can significantly impact intelligibility. Phonetic coverage and balance help ensure we capture this variability.
Lexical characteristics, though less frequently considered, can also affect intelligibility. Word frequency—how common a word is in the language—matters because more frequent words are generally more easily understood. Additionally, neighborhood density refers to how many other words in the language sound similar to a given word. Words in dense neighborhoods, like “cat,” which can be confused with “cap” or “bat,” may be more difficult to understand compared to words in sparse neighborhoods like “watermelon,” which has fewer similar-sounding alternatives. This difference can influence intelligibility as well.
Evidence. So, let’s consider the evidence for how different speech samples perform with respect to these key considerations. Starting with repeatability: sentences are repeatable because they come from large databases, and personalized sentences can be constructed in a way that makes them repeatable—this depends on how they are designed. However, standardized passages like the Rainbow Passage are not repeatable for assessing intelligibility due to potential practice effects for the speaker and learning effects for the listener. While these passages can be useful for assessing treatment progress, they aren't ideal for repeated measures of perception.
As for reading ability, almost all of the stimuli discussed here, with the exception of conversation, require reading.
Next, let's look at phonetic characteristics. In work by Lammert and colleagues, phonetic balance is achieved more consistently in passages (2020). Passages like the Rainbow and Caterpillar, as well as the TIMIT sentences, are designed to be phonetically balanced. The Harvard sentences are described as being phonetically balanced by their developers, but there’s no published evidence to confirm this. Phonetic coverage, which ensures a variety of speech sounds are included, is achieved in passages like The Rainbow and Caterpillar, though there’s less evidence for whether this is true for sentence-level stimuli.
Lexical features have been less explored. However, Kaila Stipancic and colleagues examined the lexical features of the AIDS and SIT sentences and found that while the entire database is well-balanced in terms of word frequency and neighborhood density, individual samples used for assessing intelligibility might not be (2023). That said, repeated use of the database likely balances out these effects over time.
Now, how long should your speech sample be? If you’re following a published protocol like the AIDS or SIT, the length is prescribed—typically 11 sentences for the AIDS or SIT and 10 sentences per set for the Harvard sentences. With TIMIT sentences, you can choose how many you draw from the database, and if you’re developing personalized sentences or conversational prompts, you have the flexibility to determine length. Passage lengths will naturally vary.
We don't have much evidence guiding how long a speech sample should be. This particular question hasn’t been thoroughly explored, but I can share some of our work with the SIT and AIDS sentences, where we aimed to see if we could shorten the set of sentences and still get an accurate intelligibility assessment.
This is a complicated figure, so I'll walk you through it.
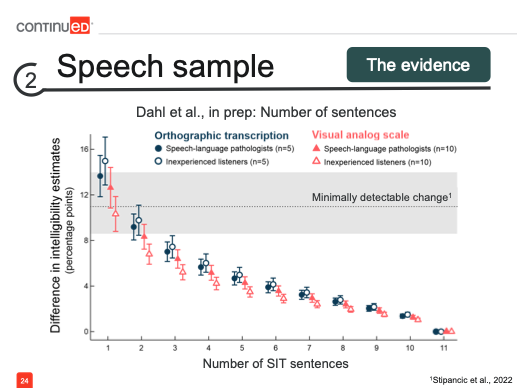
We had both speech-language pathologists, represented by the closed markers, and inexperienced listeners, represented by the open markers, evaluate intelligibility using orthographic transcription (blue circles) and visual analog scale (pink triangles). Along the x-axis, we began with the complete set of 11 SIT sentences and then examined what would happen if we presented only a subset. We observed that, as expected, with fewer sentences, the intelligibility estimates moved further from this benchmark estimate. However, since intelligibility can vary each time it’s assessed, the key question was whether this shift was significant enough to be concerning.
To determine this, we used the concept of minimally detectable change (MDC). The MDC accounts for inherent variability in repeated assessments and helps us identify when a change is significant enough to indicate a true difference, rather than just measurement error. As long as the difference between the benchmark and the shortened set remains within the MDC, we can consider the intelligibility measure accurate enough for tracking treatment effects or disease progression.
In the graph, we see that we can reduce the sample to as few as three sentences from the original set of 11, and still stay within the minimally detectable change range. This suggests that even with a shorter speech sample, we can achieve a reasonably accurate measure of intelligibility.
While this is promising evidence that short speech samples can be effective, I’m not suggesting that we settle on three sentences just yet. We’ll revisit this point as we tie together all the decisions involved in assessing intelligibility.
Our takeaways for speech samples are that repeatable stimuli are particularly important for tracking treatment and disease progression. This makes it a key consideration when selecting the samples we use. Standardized stimuli also help control for phonetic and lexical confounds, and we should keep these factors in mind when developing our own materials.
Takeaways. When it comes to speech samples, our takeaways are that repeatable stimuli are particularly important for tracking treatment and disease progression, making them a key consideration for the samples we choose. Standardized stimuli help control for phonetic and lexical confounds, and when developing our own materials, it's important to keep these factors in mind. Conversational samples are excellent for eliminating the reading burden, especially if that's appropriate for your patient. We may also be able to prioritize efficiency by reducing the number of sentences we present. However, we'll leave that as a question mark for now, as we’ll explore this further as we move forward.
Listeners
So, let’s move on to our next domain of decision-making: the listener. The first big question is, Can I be the listener? Can I, as the clinician, be the one to evaluate someone's intelligibility? This is an important question because access to other listeners will vary depending on the setting in which we’re practicing.
For instance, do we have colleagues who have the time to listen to a sample from our patient so that we don’t have to serve as the listener? In some cases, that may not be feasible. This leads to the important consideration of how familiarity with the speaker might affect our ability to assess their intelligibility accurately.
Evidence. What does the evidence tell us about this question: Can we, as clinicians, be the listeners when evaluating intelligibility? Researchers have examined the effect of familiarity, comparing intelligibility estimates from familiar versus unfamiliar listeners. Before diving into that, let's clarify the difference between familiar and experienced. Experienced versus inexperienced listeners refer to professional training, such as comparing SLPs to novice listeners. Familiarity, on the other hand, is about how well a listener knows a particular speaker. For example, as a clinician, I may be experienced, but when I first meet a patient with dysarthria, I am unfamiliar with their speech patterns. Over time, as I work with them, I become more familiar.
In research comparing familiar and unfamiliar listeners, they found that those familiar with the speaker understood significantly more words than unfamiliar listeners. In fact, familiarity boosted comprehension by as much as 20%. That’s a substantial increase, especially when you consider that the expected gains in intelligibility from treatment are often much smaller than that.
So, just the shift from an unfamiliar listener to a familiar one can result in significant gains in intelligibility that may not be related to treatment or disease progression at all. However, if you’re in a setting where you don’t have access to other listeners—whether colleagues or novel listeners like those used in research—don’t feel discouraged. It’s still important for speakers with dysarthria to be understood by familiar listeners, as that is a meaningful outcome in itself.
Key Consideration. The key consideration here is to ensure that when you are assessing intelligibility and don’t have access to other listeners, you rely on estimates from individuals who are consistently familiar with the speaker over time. This could mean turning to family members, caregivers, friends, or colleagues of the speaker, who can provide intelligibility estimates at each time point. This way, you avoid confounding your estimates by the natural shift that occurs as you, as the clinician, move from being an unfamiliar listener to a familiar one.
Now, what about using tools like Siri, Alexa, or ChatGPT, or other automated transcription and speech recognition systems? Could they serve as the listener? These tools can quickly transcribe speech, many are free and easy to access, and they help address the familiarity concern. For some speakers, using these speech recognition tools might even be ecologically valid if they regularly interact with such technology.
Evidence. But what evidence do we have that these tools are useful for assessing intelligibility? There is some research comparing automated speech recognition, such as Google Cloud, with human transcription. The figure below illustrates the intelligibility estimates for different speakers with dysarthria when using these automated tools versus human listeners.
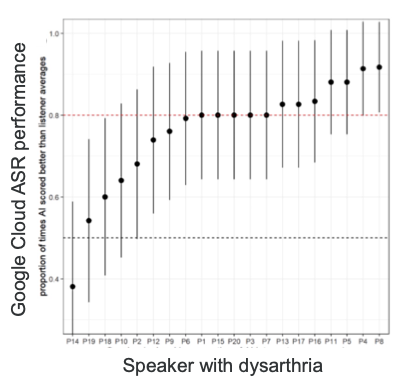
The performance of automated speech recognition here is defined by whether the sentences were transcribed as well as or better than human transcribers, with a target of 80% accuracy. For about half of the speakers with dysarthria, the automated tools met or exceeded this 80% threshold.
However, I want to focus on the criteria of as well as or better than. In clinical practice, what we're most concerned with is whether these automated tools perform equivalently to human transcribers, not necessarily better. While this is interesting evidence, it presents challenges for clinical interpretation. We would prefer tools that provide results closely aligned with human transcribers, rather than just surpassing a certain threshold of performance.
Research by Gutz et al. (2022) found a strong relationship between automated and human transcription, which is promising, but it was a nonlinear relationship. Notably, for speakers with mild dysarthria, the relationship between automated and human transcription was weakest. This is important to keep in mind—automated tools tend to perform less like humans when transcribing mildly dysarthric speech.
Now, if we decide to recruit human listeners, who should they be? We have a few options. One option is to recruit listeners inexperienced with dysarthric speech, which is often considered ideal because they represent the people with whom speakers with dysarthria interact daily, outside of clinical or research settings. However, these listeners can be harder to recruit in clinical environments.
On the other hand, we could turn to colleagues or others experienced with dysarthric speech. These listeners can help us compare results across clinical settings or between clinicians, which can be useful. However, experienced listeners are more challenging to recruit in research settings, where we often aim to measure intelligibility for broader purposes.
What evidence do we have about any differences in intelligibility estimates between these listener groups? Let’s turn again to the work by Micah Hirsch and colleagues. They compared intelligibility estimates between SLPs and inexperienced listeners.
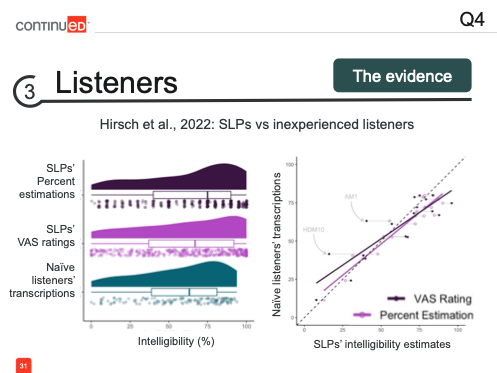
Let's start with the panel on the left. If we take the bottom distribution of ratings from inexperienced listeners as the "ground truth"—since these novice listeners are considered representative of most listeners out in the world—and these were their transcriptions, which we’ve already established as the most objective measure of intelligibility, we can use this as a baseline. When comparing this to the ratings by SLPs using different methods, such as percent estimation and VAS, we observe that SLPs tended to overestimate intelligibility. Both the mode and the mean of the SLP ratings are slightly higher than those of the inexperienced listeners.
This relationship is further shown here, where the study looked at whether SLPs' intelligibility estimates predicted those same estimates from the inexperienced listeners. While there is a strong relationship, there is a slight tendency for SLPs to overestimate intelligibility compared to inexperienced listeners.
In my own work with colleagues at the StepLab, we also compared the ratings from SLPs and inexperienced listeners using both orthographic transcription and the visual analog scale (VAS).
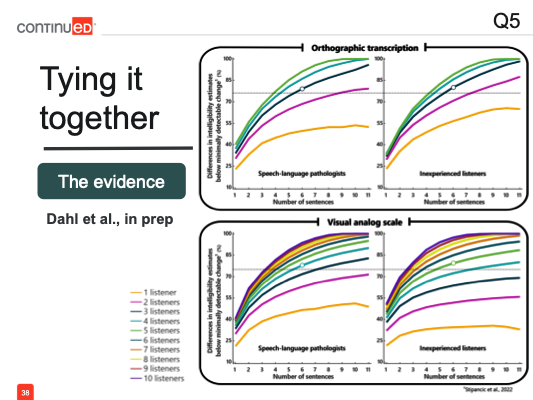
Encouragingly, in our work at the StepLab, we found near-perfect agreement between SLPs and inexperienced listeners when using orthographic transcription, supporting the idea that this is a more objective way to measure intelligibility, not influenced by listener experience. With the visual analog scale (VAS), we still saw a very strong relationship and high agreement between the two groups. However, there was a slight tendency for SLPs to overestimate intelligibility. For example, when SLPs rated speakers as 80% intelligible using the VAS, those same speakers were rated closer to 65% intelligible by inexperienced listeners. This is an important point to keep in mind when comparing estimates from SLPs and inexperienced listeners, especially considering the SLPs’ tendency to overestimate intelligibility depending on the method used.
Now, how many listeners do we need? We’ve discussed the inherent variability in measuring intelligibility, and multiple listeners can help reduce measurement error, as shown by research. Abur and colleagues demonstrated that as more listeners were added to the process of assessing intelligibility, the accuracy of those estimates improved (2019). However, the most significant improvement in measurement accuracy came from increasing the number of listeners from one to just two. While adding more listeners is beneficial—particularly in research settings—it’s not always feasible in clinical practice to recruit 5, 10, or 15 listeners per patient. That said, even just adding a second listener can yield substantial gains in accuracy.
One caveat to this research is that it involved inexperienced listeners assessing intelligibility using SIT sentences. Based on expected changes with treatment, the criterion for accuracy was a 7% change in intelligibility.
Takeaways. What do we want to keep in mind? First, we need to consider the issue of familiarity—familiar listeners may not accurately capture overall intelligibility. Most importantly, we should avoid measuring the effects of treatment or disease progression by mixing familiar and unfamiliar listeners, as this could distort the results. Automated assessments show promising potential, but the evidence is still preliminary, and there are questions about how to effectively integrate these tools into clinical practice.
Additionally, experienced listeners, such as SLPs, may overestimate intelligibility with certain assessment methods compared to inexperienced listeners. Finally, while the research suggests we may only need as few as two listeners to gain a more accurate measure of intelligibility, this point remains under consideration as we bring all these factors together.
So now, let’s tie everything together.
Tying It Together
We’ve considered method, speech sample, and listeners separately. Now, how do these decisions interact? When it comes to method, we know there are multiple valid options. We can prioritize either objectivity or efficiency and still obtain accurate measures of intelligibility—these priorities aren’t necessarily in competition. In terms of the speech sample, we have some evidence suggesting that as few as three sentences might be sufficient, but that finding came from research involving five to ten listeners. Similarly, while using as few as two listeners may be enough, that research involved transcribing eleven SIT sentences.
So, as we make decisions in one area, how do those choices impact the decisions we need to make in other areas? To explore this, let’s look at some research where we aimed to address these questions and bring everything together. I’ll walk you through this somewhat complicated figure to illustrate how these factors interact.
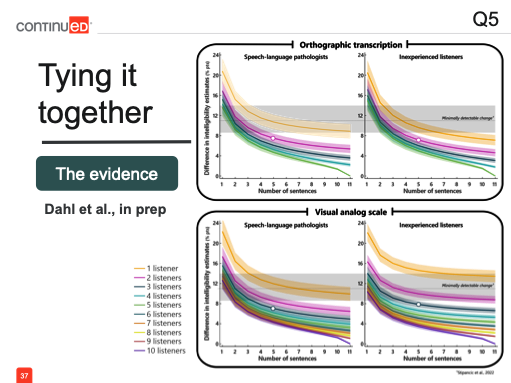
In our work, we had both SLPs and inexperienced listeners evaluating intelligibility. In both panels, SLPs are shown on the left, and inexperienced listeners on the right. Some participants used orthographic transcription (top two panels), while others used a visual analog scale (VAS). Similar to the figure shown earlier, the number of SIT sentences is along the x-axis, and the number of listeners is represented by the different lines.
In each panel, the top orange line represents a single listener, with each subsequent line below representing the addition of another listener into the process. Since transcription is the more objective approach, we incorporated five listeners, and for the more variable VAS approach, we included up to ten listeners. The graph shows the difference in intelligibility estimates as we move away from the best possible estimate, which includes all sentences and listeners. This benchmark, based on all eleven sentences and the full number of listeners, represents the most accurate intelligibility assessment for each speaker.
As expected, when we reduce the number of sentences, the curves move further away from the benchmark estimate. This pattern holds true for both listener groups and across both assessment methods. Similarly, as we decrease the number of listeners, the estimates deviate further from the most accurate intelligibility assessment.
Importantly, this movement away from the benchmark occurs regardless of listener experience and regardless of the method used to estimate intelligibility. We’re again interpreting these results in the context of the minimally detectable change. Despite the variation, if we remain below this threshold, we can be confident that the assessment is still accurate enough to detect change.
Based on this data, we might conclude that presenting just five sentences to two listeners, regardless of their experience, can still yield an intelligibility measure accurate enough to monitor change—if using transcription. For a faster method like VAS, presenting five sentences to three listeners, regardless of their experience, can also provide a sufficient measure of intelligibility.
However, I would caution you to take these findings with a grain of salt. The way we analyzed this data was by using a large database of intelligibility estimates and simulating every possible combination of sentences and listeners, taking the averages of each combination. This gave us an overview of trends across tens of thousands of simulations, so while it’s useful for understanding general patterns, it’s less precise for guiding specific decision-making. What we’re more interested in is determining the likelihood that using a certain number of sentences and listeners will give us an intelligibility estimate accurate enough to detect change. So, we evaluated our results in that way.
Looking at the graph, we see SLPs on the left, inexperienced listeners on the right, transcription on the top panel, and the visual analog scale (VAS) on the bottom. What we’re examining now is, as we simulated all these combinations of sentences and listeners, how many of those intelligibility estimates remained below the minimally detectable change threshold—meaning they were still accurate enough to be used clinically.
The results tell a different story. Here, a single listener is represented by the line at the bottom, with each additional listener moving the line upward. Previously, based on average performance, we concluded that presenting five sentences to two listeners—whether SLPs or inexperienced listeners—would yield an accurate estimate of intelligibility.
However, when we look at it in terms of the likelihood of that estimate being accurate enough to detect change, we see that this scenario gives only about a 65% likelihood of accuracy—probably not high enough for us to confidently incorporate it into clinical practice. Instead, if we set a more robust threshold, say an 80% likelihood (a standard drawn from statistical power conventions), our decisions would shift.
Now, to achieve an 80% certainty that our intelligibility assessment would be accurate enough to detect treatment-related changes, we would need to present at least six sentences to three listeners, regardless of their experience. Alternatively, if using a more efficient method like a VAS, we would need six sentences presented to four SLPs or five inexperienced listeners. These results help guide us in structuring intelligibility assessments based on what’s most important in a given setting.
For most of us in clinical practice, the priority is likely to minimize the number of listeners involved. In that case, you’d look for the lowest line that remains above the minimum threshold, such as 80%. For instance, if you only have access to a second listener, and they are an SLP, you’d need to present nearly the full set—ten or eleven sentences—to get an intelligibility estimate you can trust.
We’re also launching a tool through the StepLab that will let you customize this process. You’ll be able to input fixed elements like using only SLPs, relying on VAS or transcription, or limiting the number of listeners. The tool will help you figure out your best options for assessing intelligibility accurately and efficiently, based on the number of sentences you present and how easily you can recruit listeners. Keep an eye out for that tool!
Summary
We've discussed methods, speech samples, and listeners, and now we’ve seen how bringing these factors together means that decisions or restrictions in one domain will impact the choices we make in the other domains. So, we want to ask ourselves a set of questions as we decide how to assess intelligibility.
What type of assessments do I have access to? Do I have formal assessments available, or will I need to use an informal assessment? If I’m using informal methods, which approach makes the most sense for my setting?
How much time do I have to assess intelligibility? Is it limited? Many of us are working under significant time constraints. If that’s the case, do I want to prioritize efficiency over objectivity?
What speech samples do I have, or can I collect? This might also relate to efficiency, or it might depend on what’s most appropriate for the patient’s particular impairment or their specific concerns regarding where they want to achieve intelligibility.
What type of listener can I easily recruit, and how many listeners can I recruit?
By considering these questions, you can identify which of these areas is the most restricted for you. This will help you determine where you have the least flexibility in decision-making, and then you can use the evidence we’ve reviewed today to guide your choices from there. Ultimately, this will allow you to devise an intelligibility assessment method that’s as accurate and practical as possible, given your constraints.
Questions and Answers
What concerns should I have about how these decisions might vary depending on the severity of the speaker's intelligibility?
There is some evidence suggesting that factors like the minimally detectable change can vary depending on the severity of the speaker’s intelligibility. For example, the tendency to overestimate or underestimate intelligibility may differ based on how severely impaired the speaker is. However, there isn’t strong evidence yet to offer clear guidance on how we should adjust our intelligibility assessment process based on severity. It’s something to keep in mind, though, and clinical intuition or experience may help you determine which approaches work best for speakers with mild versus severe impairments.
How do I approach intelligibility in acute care settings where efficiency is very important?
In acute care settings, efficiency is crucial, and this is likely why many of you reported using percent estimation to assess intelligibility. This method is perhaps the most efficient—you listen to the speaker and estimate, for example, "I understood about 65% or 85% of what they said."
However, to ensure consistency, it’s important to standardize your process as much as possible. This way, your 65% estimate means the same across all the patients you assess. Consider standardizing the prompt you use to elicit speech for the percent estimation.
These informal assessments work well for comparing your own estimates over time, but structuring the process allows for more meaningful comparisons across patients. If multiple practitioners are using this approach in the same setting, you could agree on a common speech prompt and even perform a quick calibration exercise. By listening to the same patient and comparing your estimates, you can ensure your assessments are aligned.
These tips can help maintain both efficiency and consistency in settings where on-the-spot intelligibility assessments are necessary.
Does any of the content or data in the course apply to the pediatric population?
This course was primarily focused on adult populations, as most of the research on dysarthria has centered around adults, where certain etiologies are more common. As a result, there’s less research and evidence to guide intelligibility assessments for pediatric populations. However, some of the principles we discussed can be adapted for use with children.
For example, you might need to tailor your speech tasks or stimuli differently. Many of the standardized passages and formal assessments mentioned in this course likely won’t be suitable or particularly useful for assessing intelligibility in children. Instead, personalized sets of sentences might be more helpful, focusing on the types of interactions children have in school or at home.
While it may be harder to compare pediatric results to existing norms or research data, you can create standardized procedures within your own setting. Whether in schools or pediatric clinical environments, building consistent methods for assessing intelligibility can help you track progress and make meaningful comparisons, even in the absence of extensive pediatric-focused research.
Can we use recorded samples versus live samples?
I haven’t come across specific research that directly compares recorded samples to live samples in terms of intelligibility assessment. However, one key difference to consider is the additional cues present in live speech. When using recorded speech, we’re often limited to audio-only, while live assessments may include visual cues like gestures, facial expressions, and the movement of the articulators, all of which can enhance intelligibility.
In a live setting, these non-verbal cues might aid in understanding the speaker, leading to a potential gain in intelligibility. This is something to keep in mind, especially if you are assessing intelligibility at different time points using different methods. For instance, if you use a recorded sample at one time and then assess intelligibility live at another, the added benefits of live assessment could result in an overestimation of intelligibility compared to the recorded sample. Consistency in your approach is important to avoid this potential bias.
If you're comparing the intended message to the perceived message, how do you first determine the intended message?
That’s an excellent question, and it’s why many methods rely on reading materials—because you know exactly what the speaker intends to say. This confidence in the intended message is lost when using conversational speech or spontaneous monologues, where it’s not always clear what the speaker's intended message is.
In some cases, using a conversational sample might be necessary if reading materials are not appropriate. However, this approach can be challenging because you’re not 100% certain of the intended message, making it difficult to accurately measure intelligibility. It’s also not ideal for all patients, especially those with severely impaired intelligibility, as conversational speech samples might not provide the clarity needed to confidently assess what they’re trying to communicate.
*See handout for a full list of references.
Citation
Dahl, K. (2024). Dysarthria: best practices for assessing intelligibility. SpeechPathology.com. Article 20695. Available at www.speechpathology.com
